텍스트 감성 분석과 이미지 데이터 기반의 이모티콘 추천 시스템
이 프로젝트는 동아리 KHUDA에서 진행하였습니다.
1. 연구 배경
카카오톡을 이용하는 많은 사람들이 카카오톡 이모티콘을 사용한다. 이모티콘은 중요한 감정표현의 수단이다. 현재 수많은 이모티콘이 존재하지만 역설적으로 이모티콘 선택 과정에 어려움이 발생한다. 이에 우리 팀은 텍스트를 통해 감정을 분석하고 이미지 데이터 기반으로 이모티콘을 추천해주는 시스템을 개발하고자 했다.
이미 '카카오톡 이모티콘 플러스'라는 서비스가 존재한다. 채팅창에 단어만 입력해도 상황에 딱 맞는 이모티콘을 추천해준다. 이 서비스의 사용자들을 대상으로 설문하고 연구한 논문에 따르면 다음과 같다.

이 설문 결과를 통해 사용자의 취향과 상황에 맞는 이모티콘을 추천하는 것이 중요함을 느꼈다.
우리 팀은 컨텐츠 기반 필터링을 바탕으로 개발하고자 했다.
Content-based Filtering란?
사용자가 소비한 아이템에 대해 아이템의 내용(content)이 비슷하거나 특별한 관계가 있는 다른 아이템을 추천하는 방법을 말한다.
아이템이 유사한지 확인하려면 아이템의 비슷한 정도(유사도)를 수치로 계산할 수 있어야 한다. 유사도 계산을 위해서 일반적으로 아이템을 벡터 형태로 표현하고 이들 벡터간의 유사도 계산 방법을 많이 활용한다.
표현해야 하는 데이터 범주의 영역이 넓거나 이미지와 같이 복잡한 데이터인 경우는 데이터를 고정된 크기의 벡터로 표현하는 임베딩(Embedding) 방법을 많이 사용한다.
우리 팀이 개발하고자 하는 서비스 모델은 다음과 같다.

이모티콘을 쓰는 사람 중 대부분은 자신이 주로 사용하는 이모티콘이 하나씩은 있을 것이다. 사용자가 기존에 사용했던 이모티콘을 input에 넣어 그림체가 유사한 이모티콘을 선별하고자 한다.
조금 더 자세한 모델 구조는 다음과 같다.

2. 이미지 데이터
Style Transfer의 Gram Matrix
[이론]

스타일(style)은 서로 다른 특징(feature)간의 상관관계(correlation)을 의미한다. Gij는 특징 i와 특증 j의 상관관계이다.
Gram Matrix(구글에 검색하면 잘 나와있으니 설명은 생략한다.)
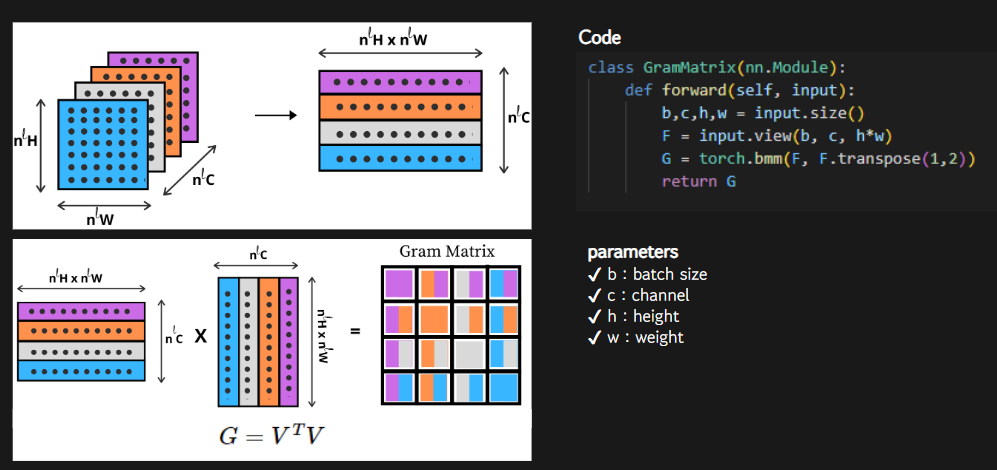
[코드]
Code를 조금 살펴 보겠다. (현재 코드 원본 파일이 날라가 ppt 자료를 참고 했습니다. ㅠㅠ)


pre-trained된 ResNet을 사용한다.
ResNet(Residual neural network)는 Skip connection 방식을 사용한다. 따라서 깊이(layer)가 깊어졌을 때 발생하는 문제를 해결할 수 있다.
그리고 shape 조절 후 list에 array를 저장했다.
그런 후 ResNet 모델을 가져와 feature 정보를 추출하고 feature 행렬을 고차원에서 2차원으로 차원 축소를 하였다. 차원 축소를 한 이유는 시각화를 위해서다.
가장 가까운 이웃 3개를 계산한 후 시각화했다. 그 결과는 아래와 같다.
참고로 이번 프로젝트에서 사용한 이모티콘은 총 50개로, 최대한 다양하게 인기 순위에서 임의로 선정하였다.

[결과]
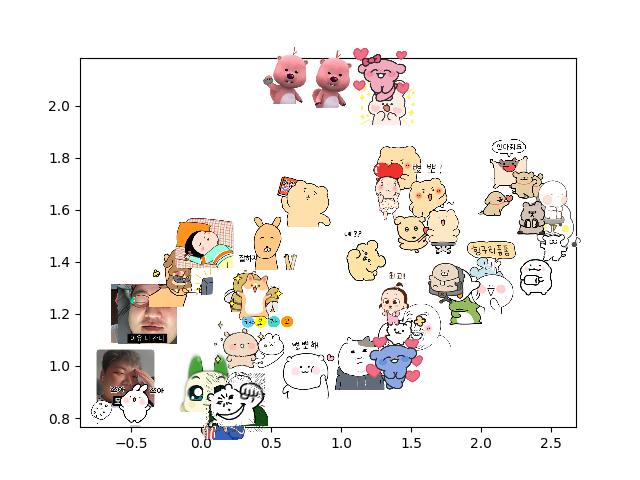
[RGB Scale]
- 색깔을 더 중요하게 반영하는 경향이 있음.
- 비슷한 그림체이지만 색깔이 다르면 잡아 내지 못함.
- 직관적으로 납득이 가지 않는 부분이 존재함.
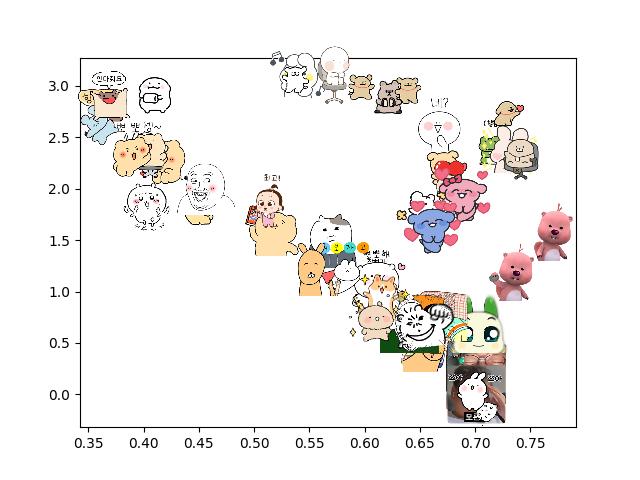
[Gray Scale]
- 색깔을 더 중요하게 반영하는 문제를 해결함.
- 하지만, 그림체의 특징을 추출하는 성능이 저하함.
- 여전히 직관적으로 납득이 가지 않는 부분이 존재함.
[문제점]
Covariance이므로 상대적이다. 즉, 매번 계산을 할 때마다 테스트 데이터를 포함하여 covariance를 계산해야 한다. 이를 2차원으로 mapping하는 t-SNE 과정이 오래걸리고 번거롭다. 또한 오래된 방법이라 성능이 뛰어나지 못하다.(직관적으로 납득이 가지 않는 부분이 존재한다.)
CLIP(Contrastive Learning In Pretraining)
[이론]

CLIP은 4억개의 (이미지, 텍스트) 쌍으로 학습된 모델이다. (이미지, 물체 분류) 데이터를 사용하는 다른 모델과는 달리 (이미지, 텍스트) 데이터를 사용하는 것이 특징이다. 전자의 경우에는 label이 지니는 정보의 양이 너무 적다는 단점이 있다. 이미지에 포함된 다양한 정보들 중 물체의 '종류'라는 단일 정보만을 표현하기 때문에 이미지가 가진 다양한 특징을 활용하는 데에는 한계가 있다. 그래서 우리 팀은 CLIP을 사용하고자 했다.
우리 팀은 이모티콘의 썸네일의 특징 추출을 할 것이기 때문에 이미지 인코더 부분만 사용했다.
N개의 (텍스트, 이미지) 쌍의 배치가 주어진다고 할 때, CLIP은 그림에서 보다시피 N*N의 가능한 (이미지, 텍스트) 쌍을 예측하도록 학습된다. 따라서 만약 대각선에 위치한 positive pair의 코사인 유사도를 최대화 하고, 나머지 쌍들(negative pair)은 코사인 유사도를 최소화 하는 방향으로 Cross Entropy loss를 사용해 학습한다.
VIT(Vision Transformer)란?
NLP 분야에서 사용하는 Transformer를 Image Classification 분야에 맞게 약간 변형한 것이다.

이미지를 Patch로 분할 후 Sequence로 입력다. 이는 NLP에서 단어가 입력되는 방식과 동일하다.
[코드]
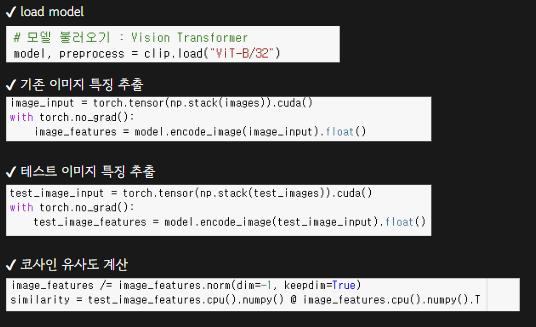
[결과]

이미지 오른쪽 상단에 루피(결과: 파란색)와 사람 이미지(결과: 빨간색)를 입력으로 넣은 결과이다. 유사도가 가장 높은 5개를 체크 해두었다.
루피에 대한 결과를 보면 먼저 루피와 똑같은 시리즈인 이모티콘들은 모두 유사도가 가장 높게 나왔고 루피와 비슷한 포즈를 한 동물들이 그 다음으로 높게 나온 것을 확인할 수 있다.
사람 이미지에 대한 결과를 보면 똑같은 실제 사람 이모티콘의 유사도가 가장 높게 나온 것을 확인할 수 있고 실제 사람은 아니지만 사람 형태를 한 이모티콘이 그 다음으로 높게 나온 것을 확인할 수 있다.
이후 투표 시스템을 추가했다.

3. 텍스트 데이터
- 감정에 맞게 이모티콘을 추천해주는 것이 주제이므로 다중 분류 모델로 학습을 진행했다.
- 충분한 대화 데이터 셋 확보가 어려워 사전 훈련된 모델을 사용했다.
- 사전 학습 모델 중 한국어로 학습한 koBERT 모델이 가장 성능이 좋다.
[데이터 수집]
아래를 참고해 총 84MB 가량의 데이터를 확보했다.
1. 한국어 감정 정보가 포함된 단발성 대화 데이터셋
2. 한국어 감정 정보가 포함된 연속적 대화 데이터셋
3. 감성대화 말뭉치
4. 온라인 구어체 말뭉치 데이터
- (https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=625)
[데이터 전처리]

- 중복되는 감정을 통합함.
- json 파일에서 필요한 내용만 추출하여 정리함.
- 필요없는 column은 제거함.
[데이터 증강]
라벨링이 되지 않은 데이터를 ChatGPT API를 이용해 라벨링을 진행했다.
Data augmentation: I want you to classify this text to '불안, 당황, 분노, 슬픔, 중립, 행복, 혐오', the text is '%sentence_input
그 결과 1.1MB의 데이터를 추가적으로 확보할 수 있었다.
[코드]

pre-trained된 KoBERT 모델을 이용했다. 분류하려는 감정 개수, 클래스 수를 6으로 설정 했다.
KoBERT에 대한 내용은 다음의 링크를 참고해 주세요. (https://velog.io/@seolini43/KOBERT%EB%A1%9C-%EB%8B%A4%EC%A4%91-%EB%B6%84%EB%A5%98-%EB%AA%A8%EB%8D%B8-%EB%A7%8C%EB%93%A4%EA%B8%B0-%ED%8C%8C%EC%9D%B4%EC%8D%ACColab)
[결과 - 1]

매 epoch마다 모델 학습 결과를 저장했고 Epoch 3 이후 test acc가 감소하여 학습을 중단 시켰다. 가장 test acc가 높게 나온 epoch3의 모델을 활용했다.

- '혐오'의 경우가 잘 드러나지 않았다. '혐오'를 '분노'에 통합시켰다.
- test acc가 0.7 정도로 train acc에 비해 낮았다.
- 행복 데이터를 기준으로 데이터 비율 재수정 후 2차학습을 진행했다.

[결과 - 2]

이번에도 epoch 3 이후에 test acc가 감소했고 가장 높게 나온 epoch3의 모델을 활용했다. 모델에 텍스트를 입력한 결과는 다음과 같다.



[한계점]
- 데이터 비율이 고르지 못했다.
- ChatGPT로 데이터 증강을 시도했으나 과연 잘 된 것인지 검증을 하지 못했다.
- 이모티콘 라벨링 과정에서 부정적인 감정이 별로 없었다.
4. 최종 결과
최종 결과는 가독성을 위해 ppt 자료를 이용 하겠다.
[Example 1]

가장 먼저 실사 인물 형태의 이모티콘을 이미지 input으로 줬을 때의 이미지 추천 결과이다.

그리고 텍스트 input을 입력하고 난 뒤 최종적으로 선정된 이모티콘들은 다음과 같다.
[Example 2]

두번째 예시로는 실제 사람은 아니지만 인물 형태의 이모티콘을 input으로 넣었다. 텍스트를 입력한 뒤 나온 최종 결과는 아래와 같다.

[Example 3]
마지막으로는 동물 형태의 이모티콘을 주로 사용한다고 가정하였다. 결과는 다음과 같다.


5. Review
생각보다 좋은 결과가 나온 것 같아 뿌듯했다. 나는 이미지 데이터를 주로 맡아 개발을 했다. 약 2주라는 정말 짧은 시간 안에 프로젝트를 진행해야 했던 터라 이론을 완벽하게 공부하지 못하고 진행한 면이 없지 않아 있다. 추후 다시 프로젝트를 리뷰하며 이론을 확실히 하는 시간을 가지면 좋을 것 같다. 팀원들이 다양한 분야를 희망하고 있었기 때문에 추천 시스템, 컴퓨터비전, 자연어 처리 분야를 모두 섞은 프로젝트가 된 것 같다. 세 분야에 대해 경험과 지식이 없었던 나로써는 정말 좋은 경험이 되지 않았나 싶다. 당장은 이 분야들을 공부할 계획은 없지만 나중에 공부하게 된다면 아마 이번 프로젝트가 도움이 되어 좀 더 수월하게 공부할 수 있을 것이라 생각한다.