다음은 책 '모두의 딥러닝'의 부록 부분에 해당하는 내용입니다.
모두의 딥러닝 - YES24
2년 연속 베스트셀러, 내용과 소스 코드 전면 업그레이드딥러닝 기초부터 최신 트렌드까지 한 권으로 공부하자그동안 딥러닝 입문서로 제 역할을 톡톡히 해낸 『모두의 딥러닝』이 최근 주목받
www.yes24.com
M. 데이터 병합하기
# 실습을 위한 데이터 프레임 만들기
import pandas as pd
adf = pd.DataFrame({"x1" : ['A', 'B', 'C'],
"x2" : [1, 2, 3]})
bdf = pd.DataFrame({"x1" : ['A', 'B', 'D'],
"x3" : ['T', 'F', 'T']})
cdf = pd.DataFrame({"x1" : ['B', 'C', 'D'],
"x3" : ['2', '3', '4']})


70. 왼쪽 열을 축으로 병합하기
# x1을 키로 해서 병합, 왼쪽(adf)을 기준으로
# 왼쪽의 adf에는 D가 없으므로 해당 값은 NaN으로 변한한다.
pd.merge(adf, bdf, how='left', on='x1')
71. 오른쪽 열을 축으로 병합하기
# x1을 키로 해서 병합, 오른쪽(bdf)을 기준으로
# 왼쪽의 bdf에는 C가 없으므로 해당 값은 NaN으로 변한한다.
pd.merge(adf, bdf, how ='right', on='x1')
72. 공통 값만 병합하기
pd.merge(adf, bdf, how='inner', on='x1')
73. 모든 값을 병합하기
pd.merge(adf, bdf, how='outer', on='x1')
74. 특정한 열을 비교해서 공통 값이 존재하는 경우만 가져오기
# adf와 bdf의 특정한 열을 비교해서 공통 값이 존재하는 경우만 가져온다.
# adf.x1열과 bdf.x1열은 A와 B가 같으므로 adf의 해당 값만 출력한다.
adf[adf.x1.isin(bdf.x1)]
75. 공통 값이 존재하는 경우 해당 값을 제외하고 병합하기
adf[~adf.x1.isin(bdf.x1)] # 해당 값만 빼고 출력한다.
76. 공통 값이 있는 것만 병합하기
pd.merge(adf, cdf)
77. 모두 병합하기
pd.merge(adf, cdf, how='outer')
78. 어디서 병합되었는지 표시하기
pd.merge(adf, cdf, how='outer', indicator=True)
79. 원하는 병합만 남기기
pd.merge(adf, cdf, how='outer', indicator=True).query('_merge=="left_only"')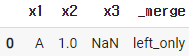
80. merge 칼럼 없애기
pd.merge(adf, cdf, how='outer', indicator=True).query('_merge=="left_only"').drop(columns=['_merge'])
N. 데이터 가공하기
df = pd.DataFrame({"a" : [4, 5, 6, 7], # 열 이름을 지정해 주고 시리즈 형태로 데이터 저장
"b" : [8, 9, 10, 11],
"c" : [12, 13, 14, 15]},
index=[1, 2, 3, 4]) # 인덱스는 1, 2, 3, 4으로 정해 준다.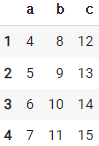
81. 행 전체를 한 칸 아래로 이동하기
df.shift(1)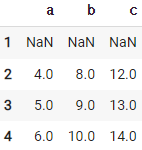
82. 행 전체를 한 칸 위로 이동하기
df.shift(-1)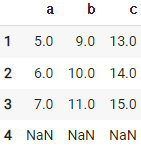
83. 첫 행부터 누적해서 더하기
df.cumsum()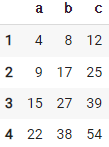
84. 새 행과 이전 행을 비교하면서 최댓값 출력하기
df.cummax()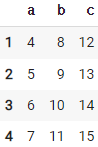
85. 새 행과 이전행을 비교하면서 최솟값 출력하기
df.cummin()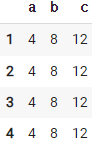
86. 첫 행부터 누적해서 곱하기
df.cumprod()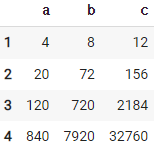
O. 그룹별로 집계하기
import pandas as pd
# 실습을 위해 데이터를 불러온다.
!git clone https://github.com/taehojo/data.git
# 15장의 주택 가격 예측 데이터를 불러온다.
df = pd.read_csv("./data/house_train.csv")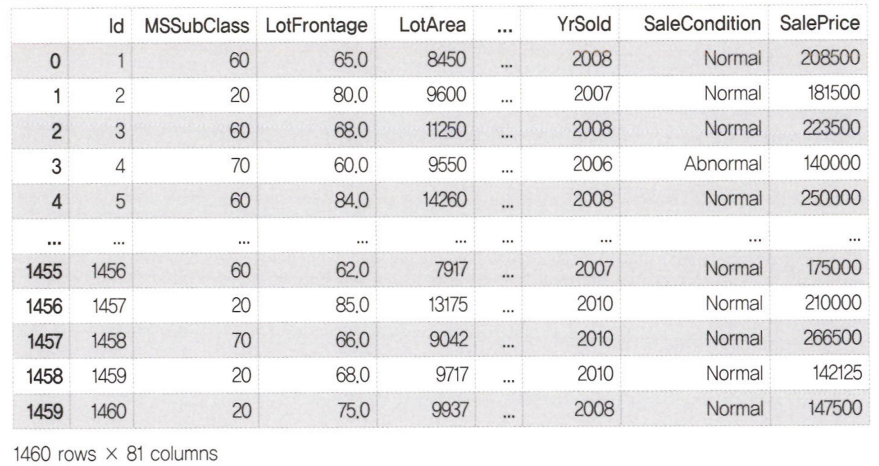
87. 그룹 지정 및 그룹별 데이터 수 표시
df.groupby(by="YrSold").size() # 팔린 연도를 중심으로 그룹을 만든 후 그룹별 수 표시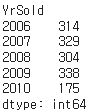
88. 그룹 지정 후 원하는 칼럼 표시하기
# 팔린 연도를 중심으로 그룹을 만든 후 각 그룹별로 주차장의 넓이를 표시한다.
df.groupby(by="YrSold")['LotArea'].mean()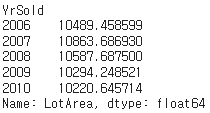
89. 밀집도 기준으로 순위 부여하기
df['SalePrice'].rank(method='dense') # 각 집 값은 밀집도를 기준으로 몇 번째인가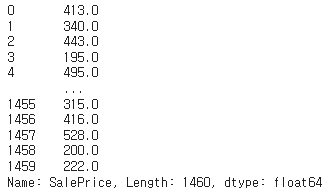
90. 최젓값을 기준으로 순위 부여하기
df['SalePrice'].rank(method='min') # 각 집 값이 최젓값을 기준으로 몇 번째인가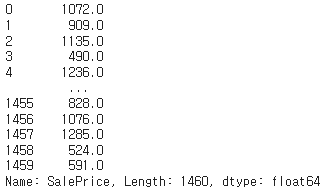
91. 순위를 비율로 표시하기
# 집 값의 순위를 비율로 표시한다(0=가장 싼 집, 1=가장 비싼 집).
df['SalePrice'].rank(pct=True)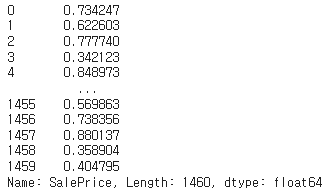
92. 동일 순위에 대한 처리 방법 정하기
# 순위가 같을 때 순서가 빠른 사람을 상위로 처리한다.
df['SalePrice'].rank(method='first')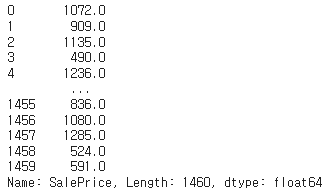
'python' 카테고리의 다른 글
| 텍스트 감성 분석과 이미지 데이터 기반의 이모티콘 추천 시스템 (2) | 2023.09.24 |
|---|---|
| [pandas] 기초 공부 3주차(I~L) (0) | 2023.02.22 |
| [pandas] 기초 공부 2주차(E~H) (0) | 2023.02.15 |
| [pandas] 기초 공부 1주차(A~D) (0) | 2023.02.09 |
| OpenCV와 Mediapipe를 이용한 가상 그림판 개발 (0) | 2023.01.18 |