다음은 책 '모두의 딥러닝'의 부록 부분에 해당하는 내용입니다.
모두의 딥러닝 - YES24
2년 연속 베스트셀러, 내용과 소스 코드 전면 업그레이드딥러닝 기초부터 최신 트렌드까지 한 권으로 공부하자그동안 딥러닝 입문서로 제 역할을 톡톡히 해낸 『모두의 딥러닝』이 최근 주목받
www.yes24.com
E. 행과 열 추출하기
28. 특정 행과 열을 지정해 가져오기
# df.loc[가져올 행, 가져올 열] 형태로 불러온다.
df.loc[:, 'a':'c'] # 모든 인덱스에서 a열부터 c열까지 가져오라는 의미이다.
29. 인덱스로 특정 행과 열 가져오기
# 0 인덱스부터 2 인덱스까지 0번째 열과 2번째 열을 가져오라는 의미(첫 열이 0번째)
df.iloc[0:3, [0, 2]]
30. 특정 열에서 조건을 만족하는 행과 열 가져오기
# a열 값이 5보다 큰 경우 a열과 c열을 출력하라는 의미이다.
df.loc[df['a']>5, ['a', 'c']]
31. 인덱스를 이용해 특정 조건을 만족하는 값 불러오기
df.iat[1, 2] # 1번째 인덱스에서 2번째 열 값을 가져온다.
# 실행결과
# 13
F. 중복 데이터 다루기
# 실습을 위해 중복된 값이 포함된 데이터 프레임을 만든다.
df = pd.DataFrame(
{"a":[4, 5, 6, 7, 7],
"b":[8, 9, 10, 11, 11],
"c":[12, 13, 14, 15, 15]},
index=pd.MultiIndex.from_tuples(
[('d', 1),('d', 2),('e', 1),('e', 2),('e', 3)],
names=['n', 'v']))
32. 특정 열에 어떤 값이 몇 개 들어 있는지 알아보기
df['a'].value_counts()
33. 데이터 프레임의 행이 몇 개인지 세어 보기
len(df)
# 실행 결과
# 534. 데이터 프레임의 행과 열이 몇 개인지 세어 보기
df.shape
# 실행 결과
# (5, 3)35. 특정 열에 유니크한 값이 몇 개인지 세어 보기
df['a'].nunique()
# 실행 결과
# 436. 데이터 프레임의 형태 한눈에 보기
df.describe()
37. 중복된 값 제거하기
df = df.drop_duplicates()
G. 데이터 파악하기
38. 각 열의 합 보기
df.sum()
39. 각 열의 값이 모두 몇 개인지 보기
df.count()
40. 각 열의 중간 값 보기
df.median()
41. 특정 열의 평균값 보기
df['b'].mean()
# 실행 결과
# 9.542. 각 열의 25%, 75%에 해당하는 수 보기
df.quantile([0.25, 0.75])
43. 각 열의 최솟값 보기
df.min()
44. 각 열의 최댓값 보기
df.max()
45. 각 열의 표준편차 보기
df.std()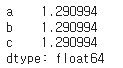
46. 데이터 프레임 각 값에 일괄 함수 적용하기
import numpy as np
df.apply(np.sqrt) # 제곱근 구하기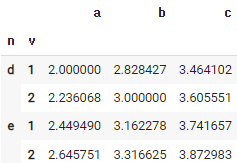
H. 결측치 다루기
# 넘파이 라이브러리를 이용해 null 값이 들어 있는 데이터 프레임 만들기
df = pd.DataFrame(
{"a":[4, 5, 6, np.nan],
"b":[7, 8, np.nan, 9],
"c":[10, np.nan, 11, 12]},
index=pd.MultiIndex.from_tuples(
[('d', 1), ('d', 2), ('e', 1), ('e', 2)],
names=['n', 'v']))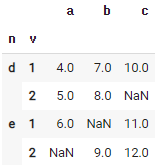
47. null 값인지 확인하기
isnull : 결측값이면 True 반환, 정상값이면 False 반환. df.isna( )와 동일함.
pd.isnull(df)
48. null 값이 아닌지 확인하기
notnull : 결측값이면 False 반환, 정상값이면 True 반환. df.notna( )와 동일함.
pd.notnull(df)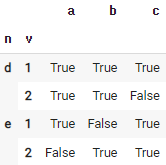
49. null 값이 있는 행 삭제하기
기본 사용법
df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)axis : {0: index / 1: columns} 결측치 제거를 진행 할 레이블이다.
how : {'any' : 존재하면 제거 / 'all' : 모두 결측치면 제거} 제거할 유형이다. 포함만 시켜도 제거할지, 전부 NA여야 제거할지 정할 수 있다.
thresh : 결측값이 아닌 값이 몇 개 미만일 경우에만 적용시키는 인수이다.
subset : dropna 메서드를 수행할 레이블을 지정한다.
inplace : 원본을 변경할지의 여부이다.
df_notnull = df.dropna()
50. null 값을 특정 값으로 대체하기
df_fillna = df.fillna(13) # 13으로 대체하는 예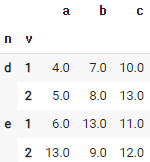
51. null 값을 특정 계산 결과로 대체하기
df_fillna_mean = df.fillna(df['a'].mean()) # a열의 평균값으로 대체한다.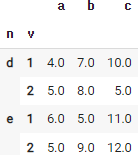
'python' 카테고리의 다른 글
| 텍스트 감성 분석과 이미지 데이터 기반의 이모티콘 추천 시스템 (2) | 2023.09.24 |
|---|---|
| [pandas] 기초 공부 4주차(M~O) (1) | 2023.03.04 |
| [pandas] 기초 공부 3주차(I~L) (0) | 2023.02.22 |
| [pandas] 기초 공부 1주차(A~D) (0) | 2023.02.09 |
| OpenCV와 Mediapipe를 이용한 가상 그림판 개발 (0) | 2023.01.18 |